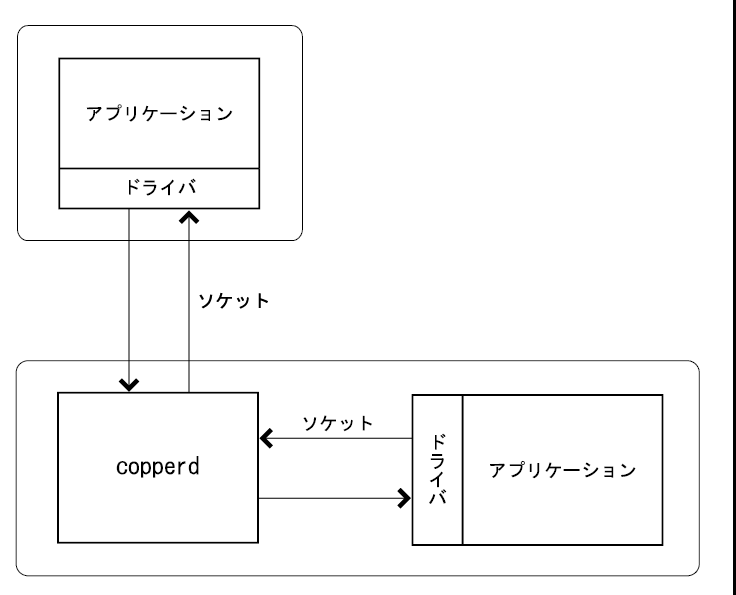
OSのバックグラウンドで動作しているCopper PDFサーバー(copperd)を、アプリケーションから呼び出すためには、ソケット通信を使います。 通信用のドライバは、各言語ごとに配布しています。 これは、一般的なデータベースサーバーと同様のしくみです。 また、Copper PDF 2.1以降ではHTTPによる接続をサポートしており、HTTPクライアントプログラムやライブラリを使用して接続することができます。 いずれにしても、ネットワーク越しの接続が可能です。
通信方式には次の3種類があります。
CTIP 1.0/2.0 によるアクセスのために、現在のところJava, Perl, PHPのドライバと、Antタスクが用意されています。 これらのプログラミング言語では、プログラミングインターフェースから高速にアクセスできます。 Java版のドライバとAntタスクはHTTP/RESTに対応しており、全く同じプログラムで両方のプロトコルを切り替えることができます。
HTTP/RESTでは、ドライバは必要とせず、各プログラミング言語からHTTPクライアントを利用してアクセスすることができます。 CTIP 1.0/2.0 と比較して、おおむね70%程度にパフォーマンスが低下しますが、 ほとんどの場合は問題となることはありません。
ドライバとcopperdとの通信は、以下の手順が基本となります。
上記のうち、2~8の手順は省略されるか、順序が入れ替わっても構いません。 10は、ドキュメントの変換中に、処理を中止したいときに実行します。 CTIP 2.0では、通信の終了をせずに、2に戻って手順を再実行することができます。 以下、各手順について順を追って説明します。
copperdにアクセスするためには、copperdのホスト名、ポート番号を知る必要があります。 これらの設定はcopperdの設定(copperd.properties)によります。 ローカルマシンで初期設定のままCopper PDFを動かしている場合、ホスト名はlocalhost(あるいは127.0.0.1(IPv4)または::1(IPv6))、 CTIPのポート番号は8099(CTIP 1.0, CTIP 2.0で共通)、HTTP/RESTのポート番号は8097です。
簡単なセキュリティ機能として、ユーザーIDとパスワードにより認証があります。 サーバーの初期設定の状態ではユーザーIDは"user"、パスワードは"kappa"ですが、 サーバー側でcopperdコマンドにより変更することができます。
copprdはクライアントのIPアドレスによりアクセスを制限します。 初期設定の状態ではローカルマシン(127.0.0.1(IPv4)または::1(IPv6))からのアクセスだけが許可されています。 これはサーバー側のアクセス制御の設定(access.txt)を編集することで起動中に変更することができます。
メッセージハンドラは、変換処理の過程で出力された警告やエラー、処理情報を受け取るためのインターフェースです (CTIP 1.0では「エラーハンドラ」という名前になっていました)。
プログレスリスナはサーバー側でのデータの処理状況をプログラムが知るためのインターフェースです。 クライアント側で処理状況をユーザーに通知させ、待ち時間の目安にするためのものであるため、 データの処理状況は必ずしも正確なものではありません。 あるいは、一切処理状況が通知されないこともあります。
変換結果はストリーム、ファイル等に出力することができます。 出力先の指定方法は、プログラミング言語によります。 Copper PDFはウェブ上での利用を重視しているため、クライアントのブラウザに送る方法は必ず用意されています。
ドキュメントを変換した結果得られるPDF、画像等のデータはクライアント側で受信してドライバにより構築されます。 出力結果はファイルに保存するか、あるいはウェブアプリケーションであればそのままユーザーに送り出すことができます。
CTIP 2.0では、複数の結果を受信することができます。 例えば、複数ページの文書を複数の画像ファイルとしてクライアント側で保存することができます。
ドキュメントの変換方法の詳細は入出力プロパティによって細かく指定することができます。 利用可能な入出力プロパティのリストは入出力プロパティ一覧を参照してください。
ドキュメントからは、様々な形で関連するCSSや画像ファイル等のリソースが参照されます。 リソースはURIによって参照されます。
URIには絶対URIと相対URIがありますが、 Copper PDFは必ずドキュメントを実際の、あるいは仮想的なURIに結びつけ、
相対URIはドキュメントのURIを基準に解決されます。 例えば、ドキュメントのURIがhttp://copper-pdf.com/docs/document.htmlであった場合、
ドキュメント中に
<img src="../images/photo.jpeg">
という記述があれば、 http://copper-pdf.com/images/photo.jpegに存在する画像が使われます。
ドキュメントのURIを相対URIとすることができます。 もっとも簡単なURIは "."(カレントディレクトリ)で、このとき相対URIで参照されたリソースの解決後のURIは相対URIのままとなります。
Copper PDFが、あるURIで参照されるリソースにアクセスする場合、3通りの方法があります。
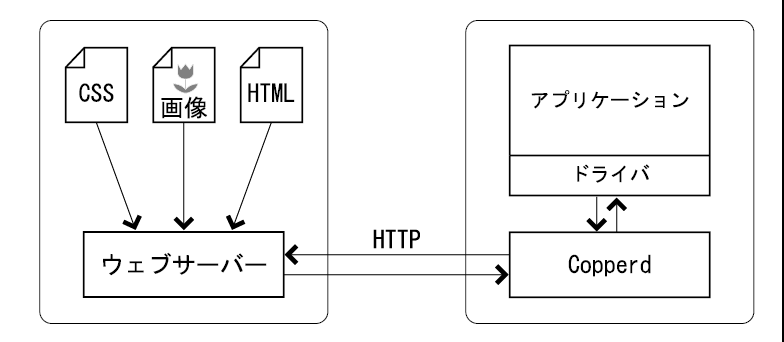
1つは、サーバーから直接アクセスする方法です。 file: で始まるURIであれば、サーバーマシン上のファイルを取得しようとします。 http: で始まるURIであれば、HTTPでネットワークから取得しようとします。 Copper PDFは、最初はこれらのアクセスを禁止するように設定されているため、 プログラムでアクセス許可する必要があります。
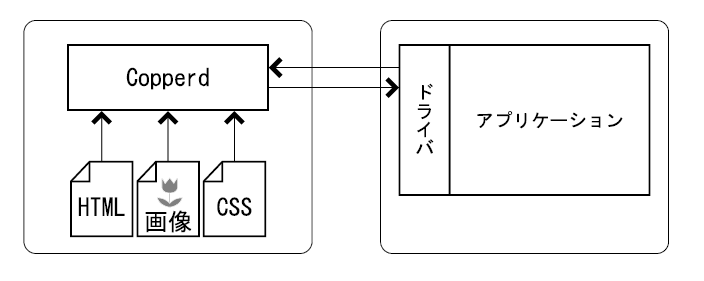
2つめは、ドライバによって、事前にクライアントからサーバーにリソースを送る方法です。 リソースを仮想的なURIに結びつけて事前に送っておくと、サーバーはそのURIのリソースを取得する際に、 実際のURIにアクセスするのではなく、事前に送ったデータを使用します。
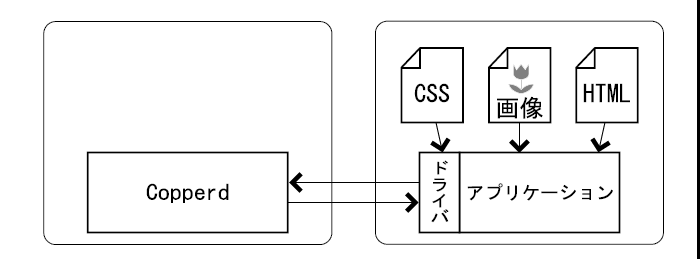
3つめはソースリゾルバ2.1.0によって、 サーバーが必要としたリソースをクライアントが送信可能であるかを問い合わせ、 送信可能なリソースを都度サーバーに送る方法です。
サーバーは最初にクライアントから送られたリソースがあるかどうかをチェックし、 なければ実際にURIアクセスすることを試みます。 また、既にクライアントから送られたリソースがある場合は、クライアントにリソースの送信を要求しません。 そのため優先順位は2番目の方法、3番目の方法、1番目の方法の順ということになります。
必要とするリソースがドライバから送られていなかった場合、 copperdは実際にそのURIで表される場所にアクセスしてデータを取得しようと試みます。
Copper PDFはHTTPクライアントを持っており、HTTP(https://で始まるURI)、SSL(https://で始まるURI)によりアクセス可能なデータを取得することができます。 またCopper PDFが動作しているローカルマシン上のファイル(file://で始まる、ブラウザでローカルマシン上のファイルを開く場合のURI)へアクセスすることができます。 データスキームURI(data:で始まる、URI中にデータを含むURI)もサポートしています。 その他のデータへはjava.net.URLを利用してアクセスするため、Java実行環境がサポートするコンテンツハンドラに依存します。
この方法の利点は、変換対象の文書から参照されているリソースを、 copperdその都度自動的に集めてくることです。 また、リソースがサーバーのディスク上にある場合は、 事前にドライバがリソースを送る(この作業は実質的には、copperdがアクセスできる場所にファイルをコピーする作業です)手間が省けるため、 パフォーマンス上有利です。
欠点として、セキュリティの問題が挙げられます。 変換対象となる文書を誰でも編集できる場合、そこにサーバー上のファイル名を指定することで、サーバー上のファイルが盗まれてしまう可能性があります。 また、http://で始まるURIを使うことで、他のサーバーへの不正なアクセスのための踏み台にされる恐れがあります。 そのため、ネットワークの構成を含めて十分に注意して運用することが必要となります。
無制限にサーバー上のリソースにアクセスされるのを防止するため、 copperdがアクセスするリソースを制限する簡単なセキュリティ機能が用意されています。 サーバー上のリソースを利用するには、適宜アクセス許可を行う必要があります。
リソースへのアクセス許可・制限は、URIパターンによって指定します。 本文の変換を始める前に、クライアントは、利用できるURIと除外するURIのパターンを指定します。
URIパターンにはワイルドカードを使うことができます。 "*"というワイルドカードは、'/'(スラッシュ)以外の任意の文字列を表します。 "**"というワイルドカードは、それに加えて'/'も含めることを表します。 ワイルドカードの例は以下の通りです。
アクセスの制御は指定された順に行われます。
例えば、最初に次のパターンへのアクセスを禁止したとします。
次に以下のパターンへのアクセスを許可したとします。
このとき、 http://www.company.com/style.css へのアクセスは許可されますが、 http://www.company.com/secret/image.jpeg へのアクセスは禁止されます。
逆に、最初に以下のパターンへのアクセスを許可したとします。
この場合は、後の指定に関係なく http://www.company.com/ 以下へのアクセスが全て許可されてしまいます。
http: または https: で始まるURIでは、%エスケープした文字は、デコードされたものとして比較されます。 また、パターンで * にマッチするようにするには、代わりに %2A を記述してください。 例えば http://www.company.com/%61bc %2A/*というパターンは http://www.company.com/a%62c*/defというURIにも http://www.company.com/ab%63%2A/defというURIにもマッチします。 2.1.7
ドライバがリソースをcopperdに送る際には、リソース本体のデータとリソースの仮想的なURIに加え、 リソースのMIME型およびキャラクタ・エンコーディングを送ることができます。 MIME型とキャラクタ・エンコーディングは必須ではなく、 省略された場合は拡張子やファイルの内容をもとにサーバー側で自動的に判断されます。 また、画像などのバイナリデータではキャラクタ・エンコーディングは無意味です。
仮想的なURIは、file:///var/data/image.gifのような絶対URIや、 data/style.cssのような相対URIです。 copperdはこれらのURIで表されるリソースが必要になった場合、 そのURIで表される実際の場所にアクセスすることはせず。 クライアント側から送られたデータを使います。 おなじURIで2度リソースを送った場合は、前のリソースは後に送られたリソースで上書きされます
この方法は、事前に画像などのデータをサーバーに送り出す手間がかかる分、パフォーマンス上不利になります。 また、アプリケーションは、本文から参照されているリソースを事前に把握している必要があります。
一方で、変換対象やリソースを1つ1つアプリケーションで指定するため、 予期しなかったファイルにアクセスされてしまうといった、セキュリティ上の危険は少なくなります。
ソースリゾルバは、サーバー側で必要とされたリソースのURIをクライアントに通知し、 可能であればクライアントからデータを送信するためのインターフェースです。 ドキュメントから参照されるリソースは、事前にクライアントから送ることができますのが、そのためには、 ドキュメントからどのリソースが参照されているのかを、クライアントが知っていることが前提となります。 しかし、HTMLからCSSが読み込まれ、さらにCSSから別のCSSや画像が参照されるといった複雑な状況では、 アプリケーションで事前に必要なリソースを解析することは困難です。 CTIP 2.0では、サーバー側でまず処理を開始し、必要になったリソースをその都度クライアントに要求し、 ドライバは要求されたリソースをサーバーに送るか、あるいはリソースの不存在を通知することができます。
CTIP 2.0では、メッセージハンドラ、プログレスリスナ、入出力プロパティの設定と、サーバー側で受信済みのリソースを全てリセットすることができます。 リセットにより、全ての状態は接続直後に戻ります。
最後にドキュメント本体をCopper PDFが変換するために必要な情報を送ります。 リソースの場合と同様、データをサーバーに送る方法と、サーバー側からデータを取得する方法があります。
変換対象のドキュメント本体をクライアントからサーバー側に送る場合は、 必ずドキュメントを仮想的なURIと結びつける必要があります。 また、必須ではありませんが、ドキュメントのMIME型とキャラクタ・エンコーディング、予測されるドキュメントサイズを明示することができます。
サーバー側でのドキュメントの変換処理は、本体の送信と並行して行われます。
サーバーに変換対処のドキュメントのURIを送ることにより、サーバー側で変換対象の文書を取得することができます。 ドキュメント中の相対パスは、ドキュメントのURIを基点に解決します。 ドキュメントのURIに対しては、URIパターンによるアクセス許可とは無関係にアクセス可能です。
ドキュメントのURIは、事前にサーバーに送ったリソースでも構いません。 ことのき、事前に送ったリソースがドキュメント本体となります。
リソースに対するアクセス禁止設定は、ドキュメント本体のURIには適用されません。
通常は、ドキュメント1つの変換処理に対して結果が出力されますが、 複数の結果を結合するモードに移行することにより、 複数のドキュメントの変換結果を結合して1つの処理結果とすることができます。
このモードでは、各々の変換処理で結果を出力することはせず、 一連の変換処理の終了をクライアントが明示した時点で、結合された結果が出力されます。
processing.pass-countにより 2パス以上の変換処理を行う場合、 それぞれのドキュメントが複数のパスで変換され、その結果が結合されます。 複数のドキュメントを通して2パス以上の変換処理を行う場合は processing.middle-pass を使ってください。
CTIP 2.0では、変換処理の最中に処理を中断することができます。 クライアントから処理の中断を要求されてから、実際に処理が中断されるまでには、若干の遅れが生じます。 処理を中断する際には、なるべくきりのよいところまで処理を継続して、途中のページまでが含まれたPDFのようなファイルが生成されるようにするか、 ファイルが破壊されても強制的に停止する2つのモードを選ぶことができますが、必ず要求どおりに処理が終わる保障はありません。
通信の終了をサーバーに通知すると、サーバーの方から接続を切断します。 CTIP 1.0では接続を切断して接続しなおさない限り、次のドキュメント変換処理は実行できませんが、 CTIP 2.0ではそのまま処理を繰り返すことができます。