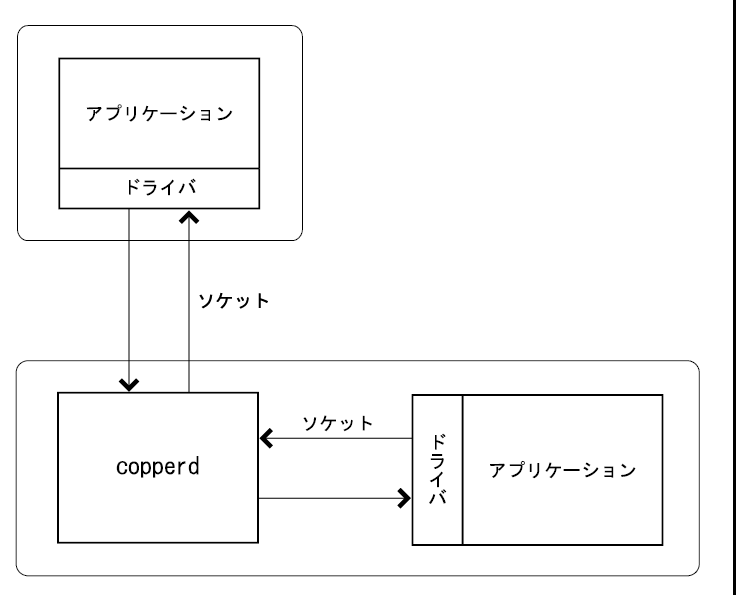
OSのバックグラウンドで動作しているCopper PDFサーバー(copperd)をアプリケーションから呼び出すためには、 各言語のために配布しているドライバが必要です。 ドライバはcopperdにソケット通信により接続します これは、一般的なデータベースサーバーと同様のしくみです。
ドライバとcopperdとの通信は、以下の手順が基本となります。
上記のうち、2, 3, 4, 5, 6の手順は省略されるか、順序が入れ替わっても構いません。 他の手順は、順序どおりに実行する必要があります。 各手順について順を追って説明します。
copperdにアクセスするためには、copperdのホスト名、ポート番号を知る必要があります。 これらはcopperdの設定(copperd.properties)によります。 ローカルマシンで初期設定のままのCopper PDFを動かしている場合、 ホスト名はlocalhost(あるいは127.0.0.1(IPv4)または::1(IPv6))、ポート番号は8099です。
簡単なセキュリティ機能として、ユーザーIDとパスワードにより認証があります。 ユーザーIDは"user"で固定です。 サーバーの初期設定の状態ではパスワードは"kappa"ですが、 サーバー側でcopperdコマンドにより変更することが出来ます。
copprdはクライアントのIPアドレスによりアクセスを制限します。 初期設定の状態ではローカルマシン(127.0.0.1(IPv4)または::1(IPv6))からのアクセスだけが許可されています。 これはサーバー側のアクセス制御の設定(access.txt)を編集することで起動中に変更することが出来ます。
エラーハンドラは、変換処理の過程で出力された警告やエラー、処理情報を受け取るためのインターフェースです (処理情報を受け取る機能は後で追加されたため「エラーハンドラ」という名前になっています)。 エラーハンドラが受け取ることが出来るメッセージは以下の4つに分類されます。
| 種類 | コード | 説明 |
|---|---|---|
| 警告 | 1 | 処理の続行が可能なエラーです。 入出力設定や、変換対象文書に問題がありますが、処理結果自体は得ることが出来ます。 |
| エラー | 2 | 処理の続行が不可能になるか、出力結果を得られなくなるエラーです。 このエラーが発生した場合、正常な処理結果が得られることは期待出来ません(PDF等のデータが壊れている可能性があります)。 |
| 致命的エラー | 3 | 通信障害など、システムの問題に起因する深刻なエラーです。 このエラーが発生した場合、正常な処理結果が得られることは期待出来ません(PDF等のデータが壊れている可能性があります)。 |
| 処理情報 | 4 | これはエラーメッセージではありません。 出力済みのページ数、処理中の内容などの情報です。 |
以上のうち、コード4の処理情報は "カテゴリ:値" という形式で渡されます (Java版のドライバではカテゴリと値を別々に受け取ることも出来ます)。 カテゴリと値は、資料集のエラーハンドラから取得出来る情報を参照してください。
プログレスリスナはサーバー側でのデータの読み込み状況や最終的なデータサイズをプログラムが知るためのインターフェースです。
プログレスリスナには、サーバー側で処理済の入力データのバイト数が渡されます。 また、プログレスリスナが要求した場合は、変換結果の先頭が得られる前に、結果全体のデータのバイト数が渡されます。 前者はプログレスバーなどでユーザーに進行状況を伝えるために利用出来ます。 後者はHTTPのContent-Lengthヘッダを送るために利用出来ます。
変換結果はストリーム、ファイル等に出力することが出来ます。 出力先の指定方法は、プログラミング言語によります。 Copper PDFはウェブ上での利用を重視しているため、クライアントのブラウザに送る方法は必ず用意されています。
ドキュメントの変換方法の詳細は入出力プロパティによって細かく指定することが出来ます。 利用可能なプロパティのリストはプロパティ一覧を参照してください。
Copper PDFで文書を変換する場合、CSSファイルや画像ファイルといったリソースがどこにあるかが問題となります。 リソースがサーバー側からアクセス出来る場所(例:copperdが動作しているマシンのディスク上)にある場合は、 copperdが直接リソースを取得出来ます。 リソースがクライアント側(ドライバを使用するアプリケーションが動いているマシン)からアクセス出来、 サーバー側からアクセス出来ない場所にある場合は、 ドライバが事前にリソースをサーバーに送る必要があります。
文書内から画像などがURLによって参照されている場合、copperdはまず、 そのURLで表されるリソースが既にドライバにより送られているかどうかを調べます。 送られている場合は、そのリソースを使います。 そうでない場合は、サーバー側でディスクやネットワーク等からリソースを取得しようと試みます。
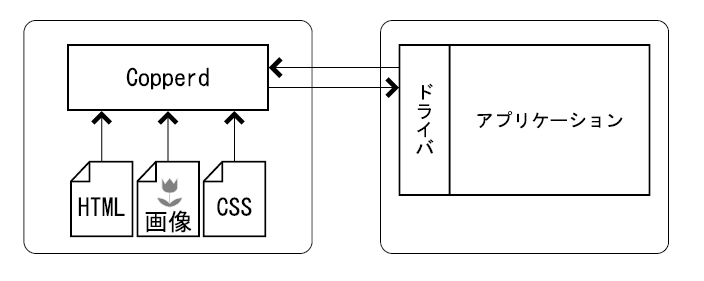
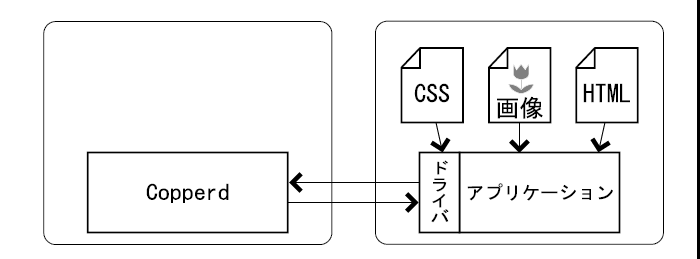
ドライバがリソースをcopperdに送る際には、リソース本体のデータとリソースの仮想的なURLに加え、 リソースのMIME型およびキャラクタ・エンコーディングを送ることが出来ます。 MIME型とキャラクタ・エンコーディングは必須ではなく、 省略された場合は拡張子やファイルの内容をもとにサーバー側で自動的に判断されます。 また、画像などのバイナリデータではキャラクタ・エンコーディングは無意味です。
仮想的なURLは、file:///var/data/image.gifや、http://host/style.cssといった文字列です。 copperdはこれらのURLで表されるリソースが必要になった場合、 そのURLで表される実際の場所にアクセスすることはせず。 クライアント側から送られたデータを使います。
この方法は、事前に画像などのデータをサーバーに送り出す手間がかかる分、パフォーマンス上不利になります。 また、アプリケーションは、本文から参照されているリソースを事前に把握している必要があります。 ドライバには必要なリソースを自動的に判断する機能がないため、 事前にどのリソースを送るかはアプリケーション側に委ねられます。
一方で、変換対象やリソースを1つ1つアプリケーションで指定するため、 予期しなかったファイルにアクセスされてしまうといった、セキュリティ上の危険は少なくなります。
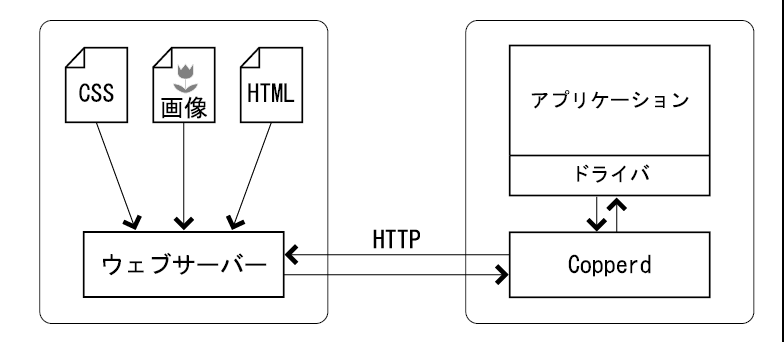
必要とするリソースがドライバから送られていなかった場合、 copperdは実際にそのURLで表される場所にアクセスしてデータを取得しようと試みます。
この方法の利点は、変換対象の文書から参照されているリソースを、 copperdその都度自動的に集めてくることです。 また、リソースがサーバーのディスク上にある場合は、 事前にドライバがリソースを送る(この作業は実質的には、copperdがアクセス出来る場所にファイルをコピーする作業です)手間が省けるため、 パフォーマンス上有利です。
欠点として、セキュリティの問題が挙げられます。 変換対象となる文書を誰でも編集出来る場合、そこにサーバー上のファイル名を指定することで、サーバー上のファイルが盗まれてしまう可能性があります。 また、http://で始まるURLを使うことで、他のサーバーへの不正なアクセスのための踏み台にされる恐れがあります。 そのため、ネットワークの構成を含めて十分に注意して運用することが必要となります。
無制限にサーバー上のリソースにアクセスされるのを防止するため、 copperdがアクセスするリソースを制限する簡単なセキュリティ機能が用意されています。 サーバー上のリソースを利用するには、適宜アクセス許可を行う必要があります。
リソースへのアクセス許可・制限は、URLパターンによって指定します。 本文の変換を始める前に、クライアントは、利用出来るURLと除外するURLのパターンを指定します。
URLパターンにはワイルドカードを使うことが出来ます。 "*"というワイルドカードは、'/'(スラッシュ)以外の任意の文字列を表します。 "**"というワイルドカードは、それに加えて'/'も含めることを表します。 ワイルドカードの例は以下の通りです。
アクセスの制御は指定された順に行われます。
例えば、最初に次のパターンへのアクセスを禁止したとします。
次に以下のパターンへのアクセスを許可したとします。
このとき、 http://www.company.com/style.css へのアクセスは許可されますが、 http://www.company.com/secret/image.jpeg へのアクセスは禁止されます。
逆に、最初に以下のパターンへのアクセスを許可したとします。
この場合は、後の指定に関係なく http://www.company.com/ 以下へのアクセスが全て許可されてしまいます。
クライアントからリソースを事前に送る方法と、サーバー側から積極的にリソースを取得する方法は、組み合わせて使うことが出来ます。 このとき、URLパターンによるアクセス制御はクライアントから送られたリソースには適用されません。 例えば、file:///var/data/*.gifへのアクセスが禁止されていたとしても、 クライアントから仮想URLfile:///var/data/image.gifとして送られたリソースは有効です。
最後にドキュメント本体をCopper PDFが変換するために必要な情報を送ります。 リソースの場合と同様、データをサーバーに送る方法と、サーバー側からデータを取得する方法があります。
リソースの場合と同様に、変換対象のドキュメント本体をサーバー側に送ることが出来ます。
このとき、ドキュメントの仮想的なURLを送る必要があります。
このURLは、ドキュメント中で使われる相対パスを解決するために使われます。
例えば、ドキュメントの仮想的なURLがhttp://copper-pdf.com/docs/document.htmlであった場合、
ドキュメント中に<img src="../images/photo.jpeg">という記述があれば、
http://copper-pdf.com/images/photo.jpegに存在する画像が使われます。
また、必須ではありませんが、ドキュメントのMIME型とキャラクタ・エンコーディングを明示することが出来ます。
サーバー側でのドキュメントの変換処理は、本体の送信と並行して行われます。
リソースの場合と同様に、サーバー側で変換対象の文書を取得することが出来ます。 このとき、ドライバから対象となるドキュメントのURLだけを送ります。 また、ドキュメント中の相対パスは、このURLにより解決します。
ドキュメント本体のURLは、事前にサーバーに送ったリソースを指定することが出来ます。 ことのき、事前に送ったリソースがドキュメント本体となります。
リソースに対するアクセス禁止設定は、ドキュメント本体のURLには適用されません。
最後に通信を完了する操作を実行する必要があります。 このとき、copperdは全ての変換結果をドライバに送り返し、接続を切断します。